
Introduction
This article is intended to describe a standardized network model for small to medium sized businesses. Outlining basic network requirements and providing recommended scenarios to improve performance, reliability, scalability and redundancy. One of the primary features in these network models is the use virtualization of server (or workstation)hardware and operating systems. This may include Windows Servers which function as an organizations Domain Controller, Terminal Server, or Mail Server, etc. Virtualization may result in the reduction of costs (less hardware; less time spent for recovery), space requirements, power consumption and allow for streamlined full system backups.
Some network environment examples will be provided to assist with understanding different levels. The focus is to show various environments ranging from basic to more advanced. Though it is notable these examples are meant to be uncomplicated and may not represent all required NW components.
Network Environments
Scenario 1 – Basic NW
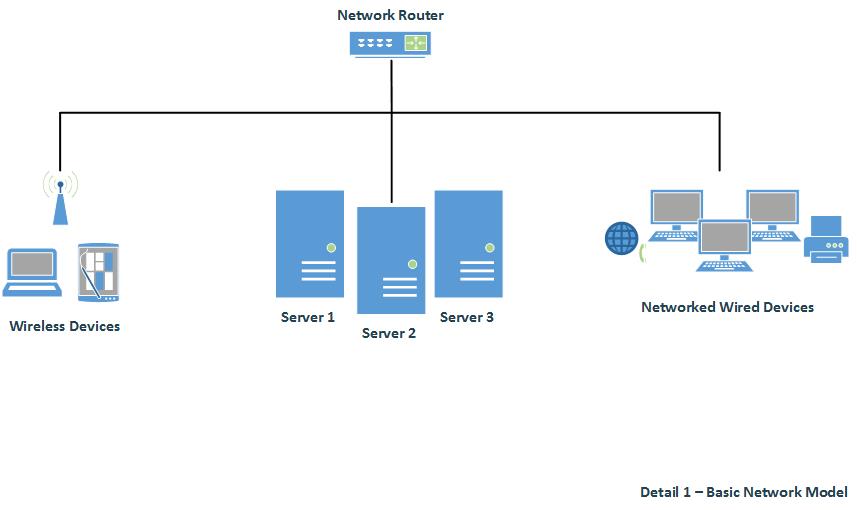
In detail 1 we see a basic network design. There is no WAN internet connection shown. This environment has no redundancy and low reliability. The server operatingsystem(s) run on physical bare metal hardware platforms. Data backups are either to the local machine or USB, while NW attached storage is not utilized. As well, system backup images have not been obtained to reinstall in case of unrecoverable software failures or hardware failures. In this non recommended scenario, the time to recover from complete OS or hardware failure would be extensive; and at high risk for data loss. Needless to say, this environment is not recommended for most,if any business
Scenario 2 – Standard NW
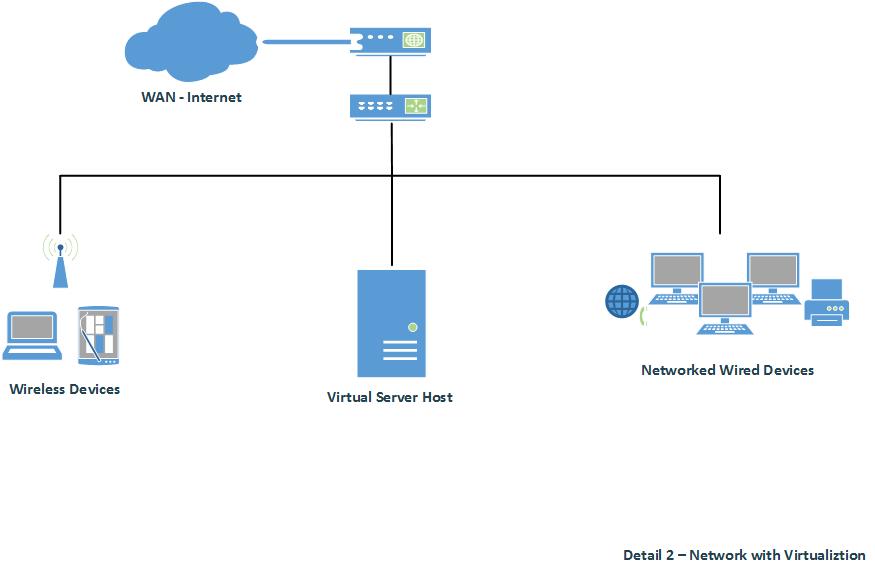
In detail 2 we see a basic network design which includes virtualization. In this environment there is no redundancy, limited backup (local storage only) and low reliability. Having no failover for the internet connection nor the virtual server host, this scenario is at high risk for extended down times and possible data loss when an issue may occur.
A problem with this scenario that may come to mind, would be: if the host machine for all of the virtual servers fails, then we have lost multiple server roles and not just one. Well, that is true in this scenario. Though, there would still be full image backups of each server. However, there would still be significant down time for rebuilding the current host or implementing a new physical machine. Now, what can be done about this problem? Let’s review scenario 3 below…
Scenario 3 – High Reliability NW
Now, let’s have a look at a recommended environment with redundancy and high reliability. In this scenario, there are a minimum of 2 virtual server host, 2 separate internet connections, 1 primary and 1 backup network router, as well as multiple backup locations (attached and unattached to the servers). Generally, most networks will have several other devices, such as switches or hubs to extend or manage NW communication. From our above described examples, we know having secondary WAN connected routers and or ISP modems is not a requirement. However, in order to show high NW availability and reliability, these options become as essential as performing routine data backups.
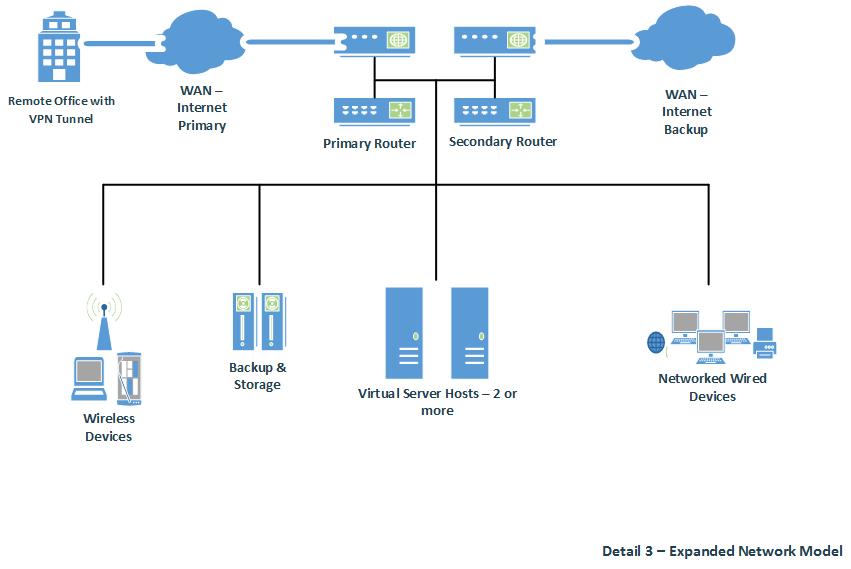
Regarding the scenario in Detail 3 (above), we have 2 or more Virtual Server Hosts in a cluster. These servers can share a dedicated storage network which allows for significantly faster backup times and reduces overall traffic on the main network. Specifically, there is a storage array managed by a hardware RAID controller independent of the operating system; and is installed on each of the virtual server hosts. With this configuration, there can be 2 or more nearly identical servers, from which each is backing up its data using a dedicated storage network to the other and or to a network storage device. Clustering the virtual server host nodes allows for management of any node via a single interface.
The second or 3rd server in this environment allows for a failure of one server to not cause any significant downtime or data loss. Meaning, if a virtual host server fails due to a hardware or software fault, one of the other servers can seamlessly take over the related tasks.
In order to take this to the next level. The use of a High Availability Cluster service can be implemented. Allowing for out of date data resynchronization due to a node failure, along with some other features such as live virtual machine migration.